

Scaling and Software Development Best Practices

I am a software professional specialising in web development and generative AI. I enjoy sharing knowledge and learning from the community. I offer consulting services and speak at events, seminars, and workshops.
Today, I attended the TechX meetup in Chennai organised by Contentstack. This is their first-ever meetup in Chennai, and I got the chance to go because of my friend Rajapandian who sent me an invite. Below is a picture of us (starting from left Sainath Ramanathan from Zensar, Ashwin from Deloitte Digital, and Rajapandian from Bank of America).

Let me dive into the topics that were discussed without further ado. The first topic was quite new to me: Open Policy Agent (OPA). This session was addressed by Ankireddy Polu, the Director of Engineering at Contentstack.
Open Policy Agent: Streamlining Compliance Through Policy as Code
Open Policy Agent (OPA) is an open-source, general-purpose policy engine that allows you to enforce policies across your stack, including applications, services, and infrastructure. It enables you to define and manage policies in a declarative way, separating policy logic from application code.
It provides a central place to define policies for different systems, such as Kubernetes, microservices, APIs, databases, or other services.
The policies are written in a high-level declarative language called Rego, which allows you to define rules and constraints for decision-making.
It evaluates decisions based on input data (HTTP requests, API calls), and policies can include logic that adapts to the current context.
It can be embedded as a sidecar or library, or it can run as a remote service, allowing it to enforce policies close to the system or component it's governing.
It enables teams to decouple policy decisions from application logic, making policies easier to update, audit, and manage without changing the underlying code.
A Simple Microservices Architecture
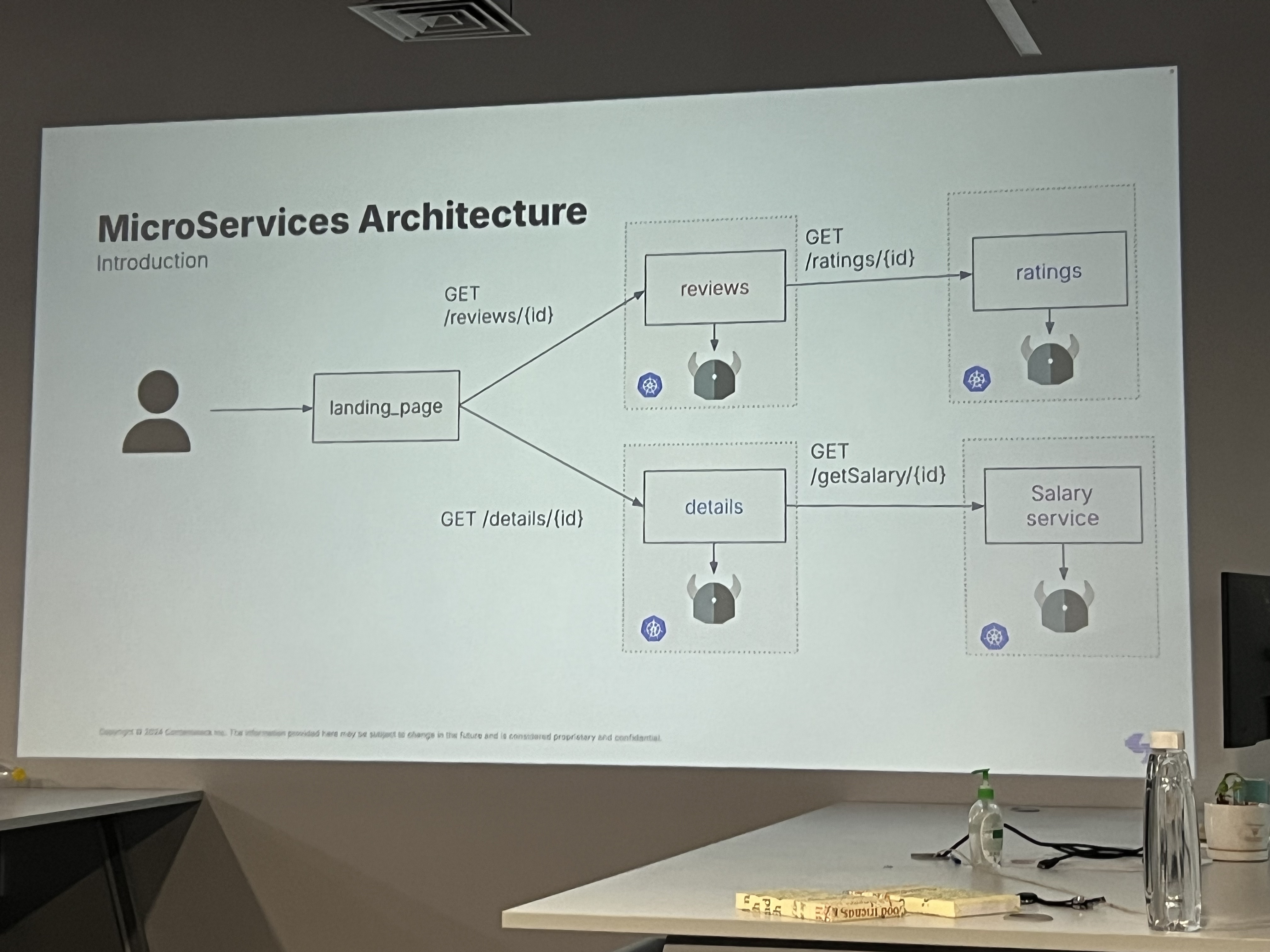
In the above image the diagram shows that each of these services operates independently, serving a specific function:
Reviews Service: GET /reviews/{id}
This service retrieves reviews for a given id (likely a product or item identifier).
Ratings Service: GET /ratings/{id}
It fetches the ratings associated with the same id. This service is consumed by the Reviews Service.
Details Service: GET /details/{id}
This service provides detailed information about the item identified by id. The details could include product descriptions, metadata, or additional features.
Salary Service: GET /getSalary/{id}
This service seems unrelated to the others, providing salary information for an identifier, possibly representing an employee or contractor.
How does OPA work?
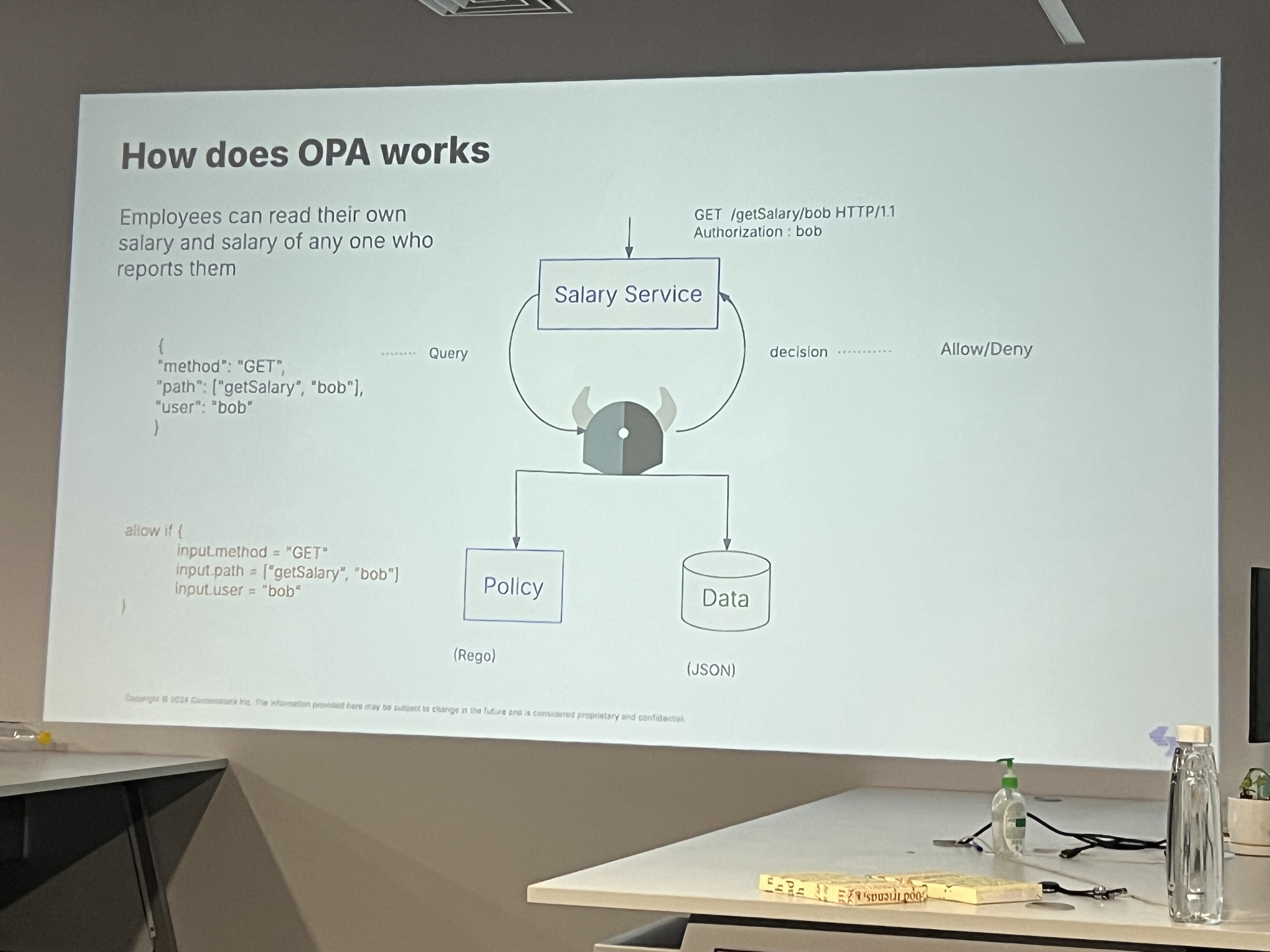
OPA evaluates policies written in its declarative Rego language. Here's the general flow:
Input Data
The microservice (e.g., Reviews or Details) sends data to OPA, such as the request path (/reviews/{id}), the requesting user’s ID or role, and any other metadata.
Policy Evaluation
OPA evaluates the request based on the predefined policies. For example:
Can a user with a certain role access the Reviews service?
Is the request made within the authorized time window?
Does the request follow rate-limiting rules?
Policy Decision
OPA returns either an Allow or Deny decision. If denied, the microservice will reject the request.
There was a live demonstration using The Rego Playground for different policies, and the session concluded with a Q&A.
The next session was by Vijayanand Chidambaram, Software Development Manager III at Amazon. This talk introduced me to a new concept called Chaos Engineering. A lot of insights were given by Vijayanand, and I have resisted myself to share only a few photos that I took as it would overload this blog. Extremely useful info coming up as you scroll down.
Effective Strategies for Handling Peak Traffic: Ensuring Optimal Performance and Scalability
Vijayanand started his talk by showcasing the details of the number of requests that happen per second typically on a Prime Day on amazon.com. The numbers were exorbitant, and a whopping 15.35 trillion requests and 764 petabytes of data transferred per day! 🤯
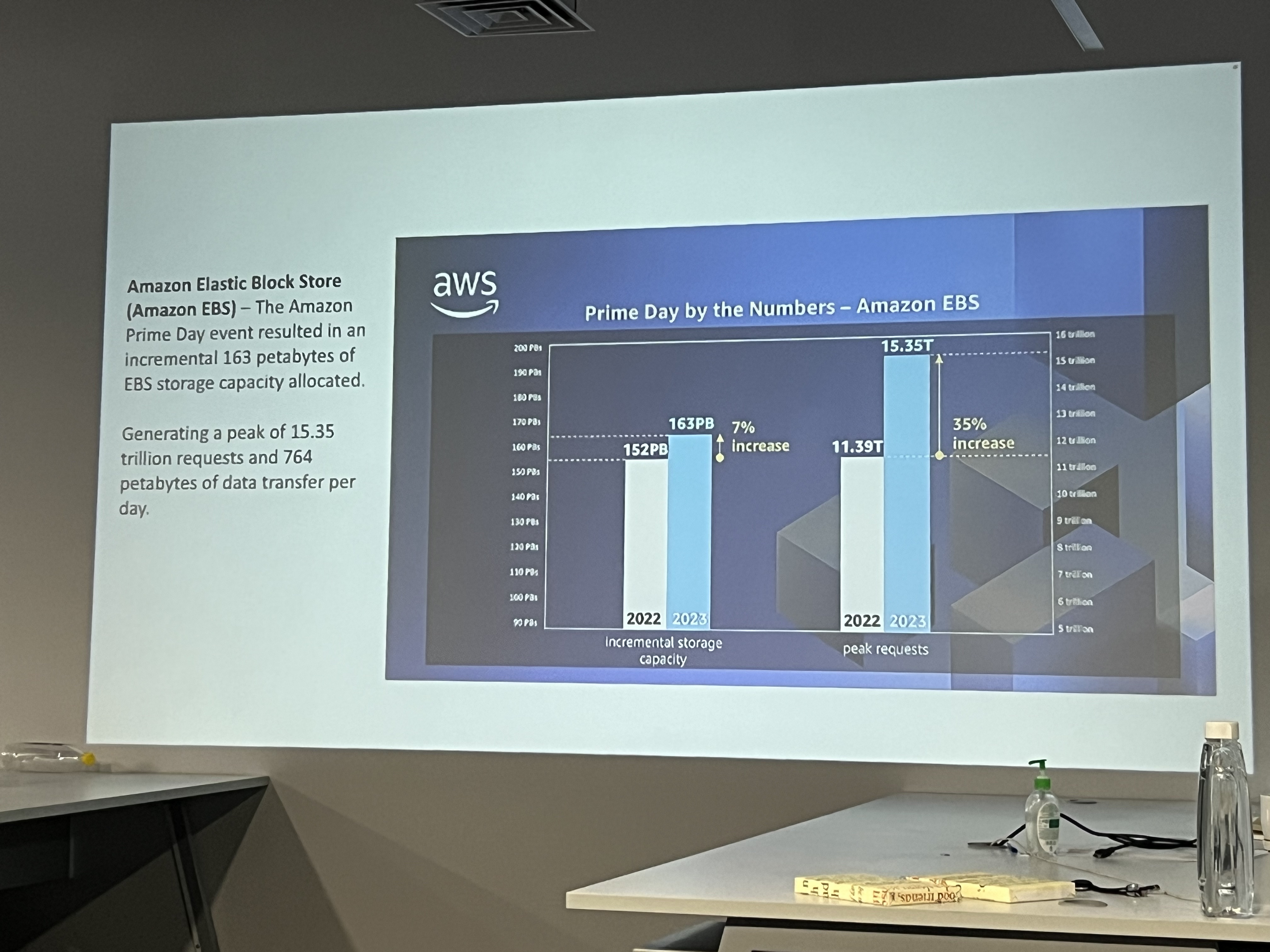
He further showcased the metrics of various AWS services (AWS CloudTrail, Amazon DyanamoDB, Amazon Aurora, Amazon Simple Email Service, Amazon CloudFront, Amazon SQS, Amazon EC2 etc.,) during the Prime Day sales.

Chaos Engineering
Chaos Engineering is the practice of intentionally injecting failures or unpredictable conditions into a system in a controlled way to test its resilience and reliability. The goal is to identify and address weaknesses before they lead to unexpected outages or failures in production. Chaos engineering helps ensure that systems can withstand disruptions and continue functioning as expected under various conditions.

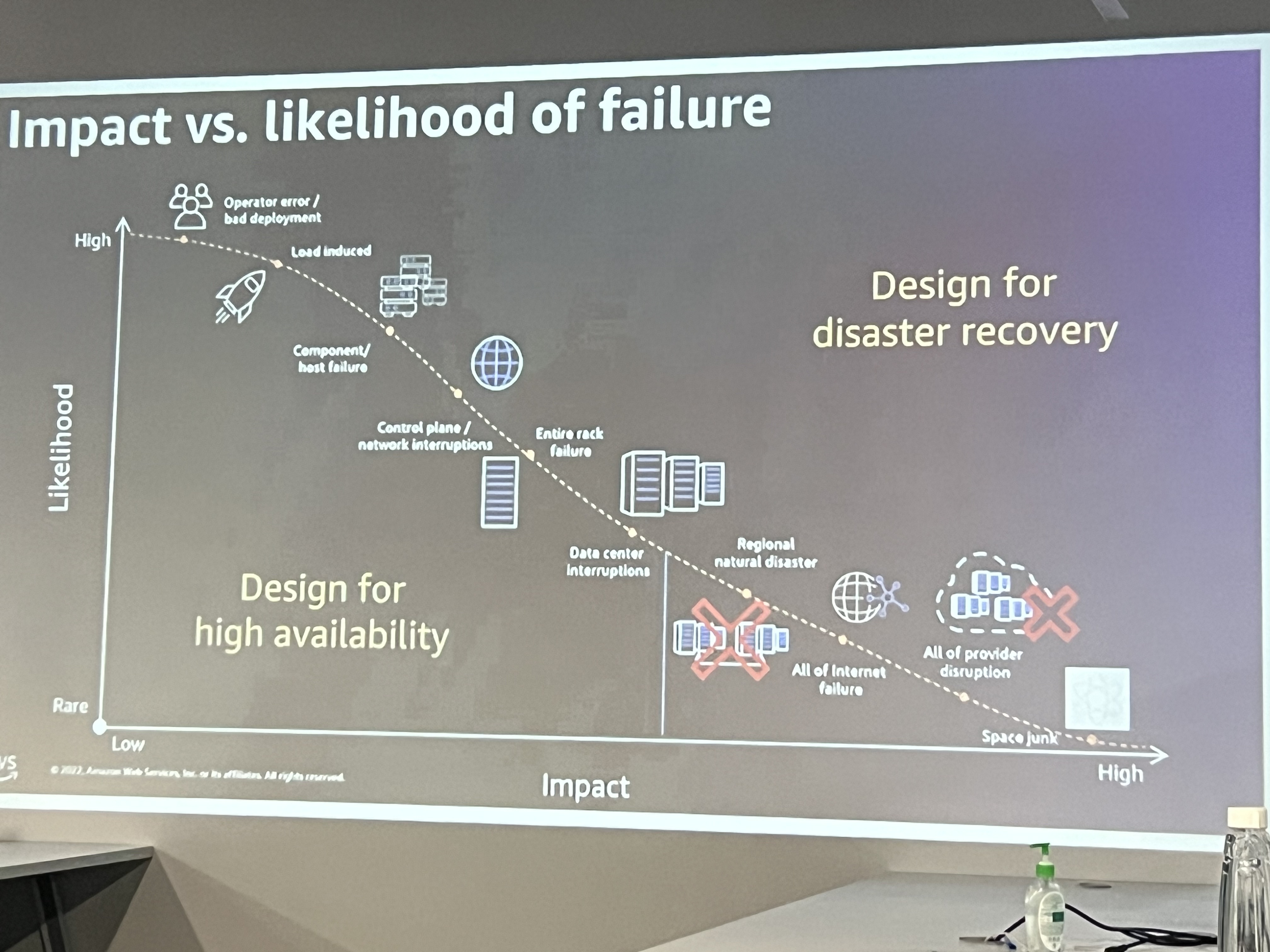
Impact vs. Likelihood of Failure is a key concept in risk management and is often used to prioritize risks, especially in fields like chaos engineering and system reliability. These failures are critical to address immediately because they are both very likely to happen and cause severe disruption. The speaker explained the combination of impact and likelihood and what it means,
High Impact + Low Likelihood: These are less frequent, but when they do occur, they can cause severe damage. These risks require strong disaster recovery and contingency plans. For example, a major data centre outage could have a high impact but may be less likely if distributed across regions.
Low Impact + High Likelihood: These failures might happen often but don't significantly disrupt the system. They should be addressed, but they may not require the same urgency. For example, a minor microservice crash that self-recovers without impacting the user experience.
Low Impact + Low Likelihood: These are minor failures that happen infrequently and don't cause much disruption. These are the lowest priority when it comes to mitigation.
Following are some of the key aspects highlighted about chaos engineering,
Operational readiness - ensuring that teams and systems are prepared to handle failures before they occur in production.
Observability - the practice of monitoring and measuring the internal state of systems based on external outputs (logs, metrics, traces).
Resilience - the system’s ability to recover quickly from failures and continue operating.
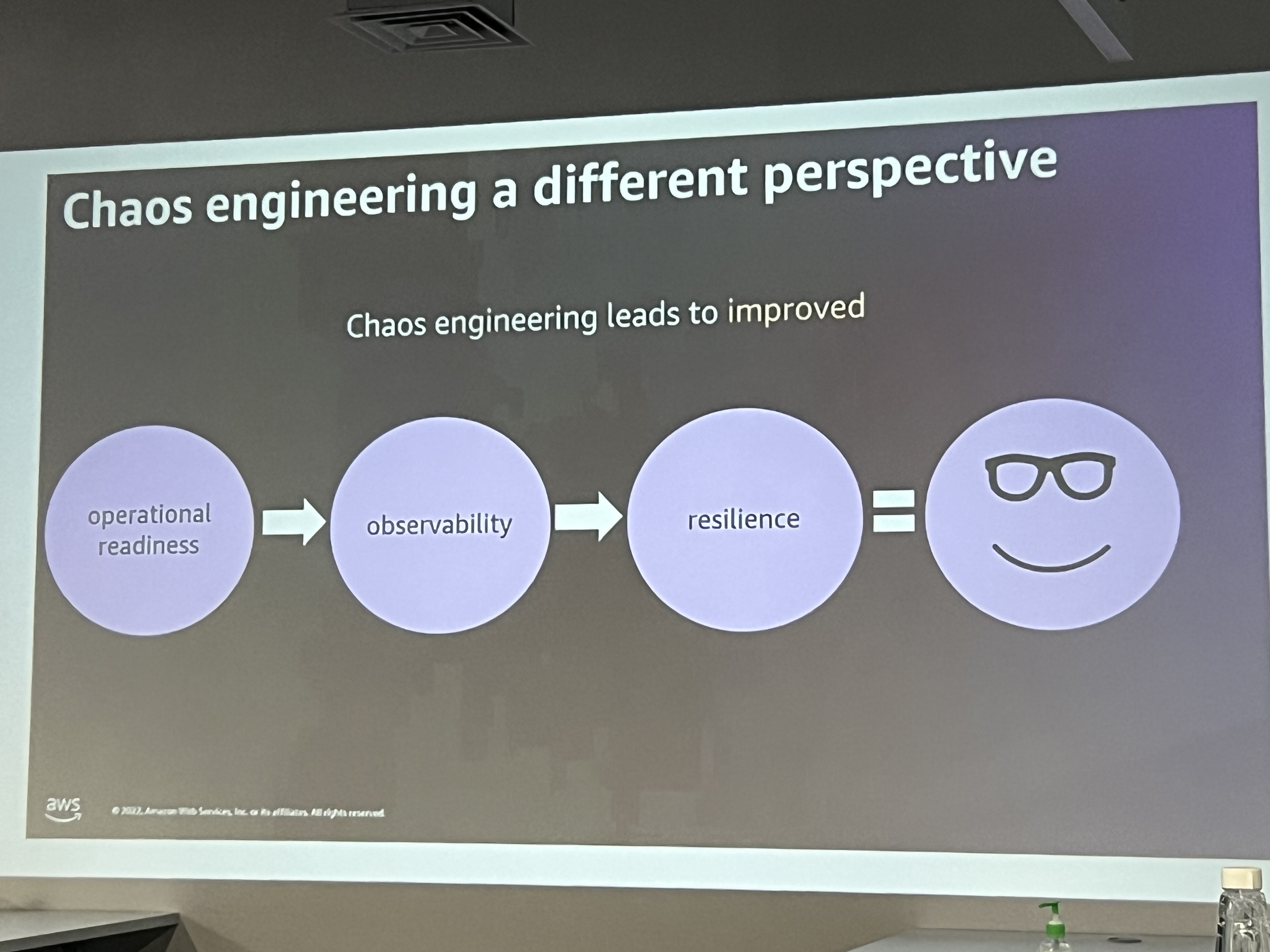
The speaker went on to explain why chaos engineering is practised, and how it ensures that systems are resilient and can withstand failures in real-world conditions. As systems, particularly microservices and cloud architectures, become more complex and distributed, the likelihood of unexpected failures increases.
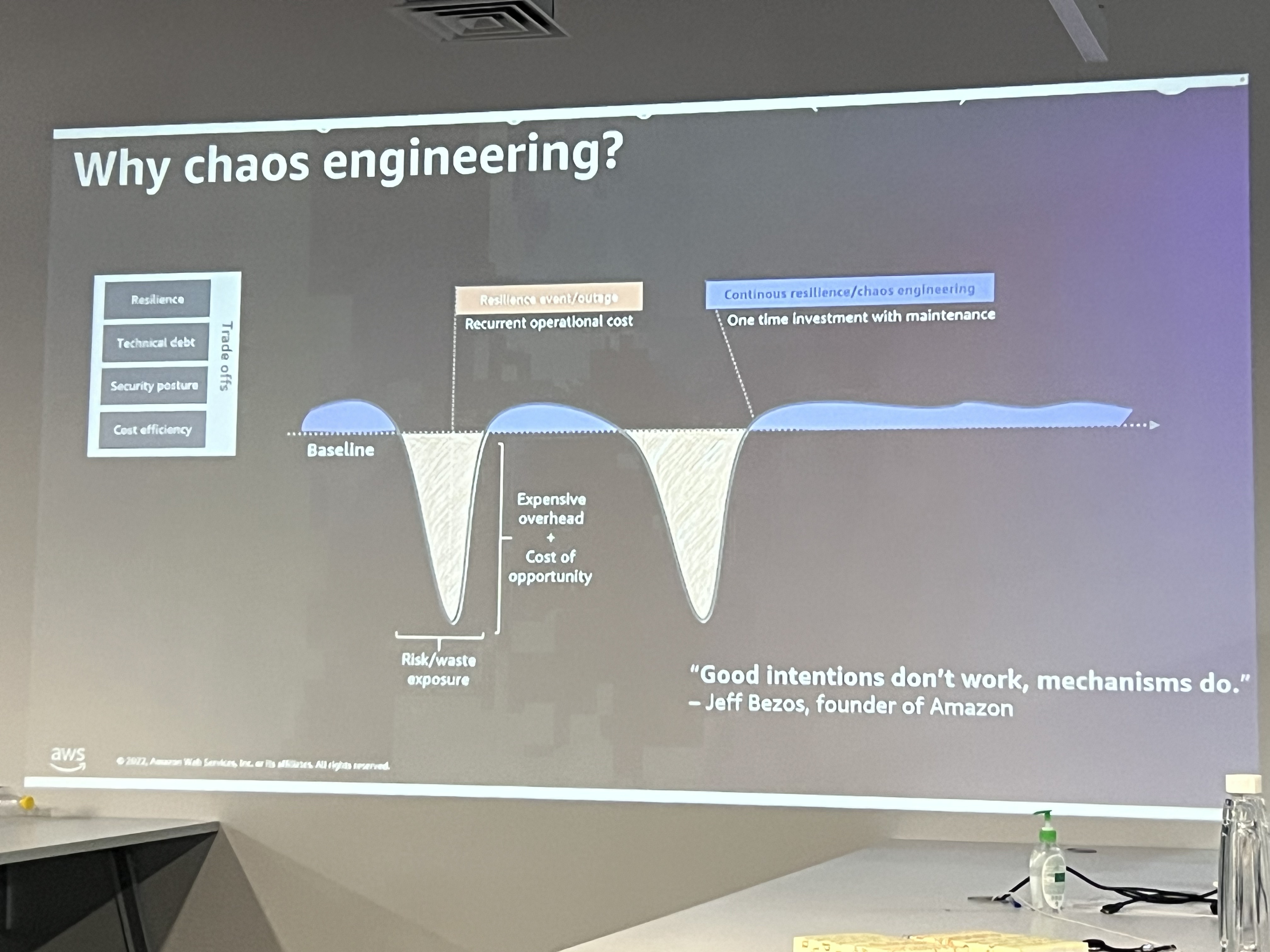
Later, several stories were discussed on how chaos engineering is increasingly being adopted across various consumer-facing sectors to enhance system resilience and improve user experience.

The fundamental step of chaos engineering is to monitor the system to observe how it behaves. The aim is to gather insights about:
How do services recover from failures?
How well do fault-tolerance mechanisms (like retries or fallbacks) work?
Identifying single points of failure or bottlenecks.
Whether the system maintains availability, performance, and security.

Chaos engineering replicates real-world conditions such as:
Network failures or delays.
Server or container crashes.
Disk or memory shortages.
Infrastructure outages (e.g., losing a data centre or region).
Dependency failures (e.g., a database going down).
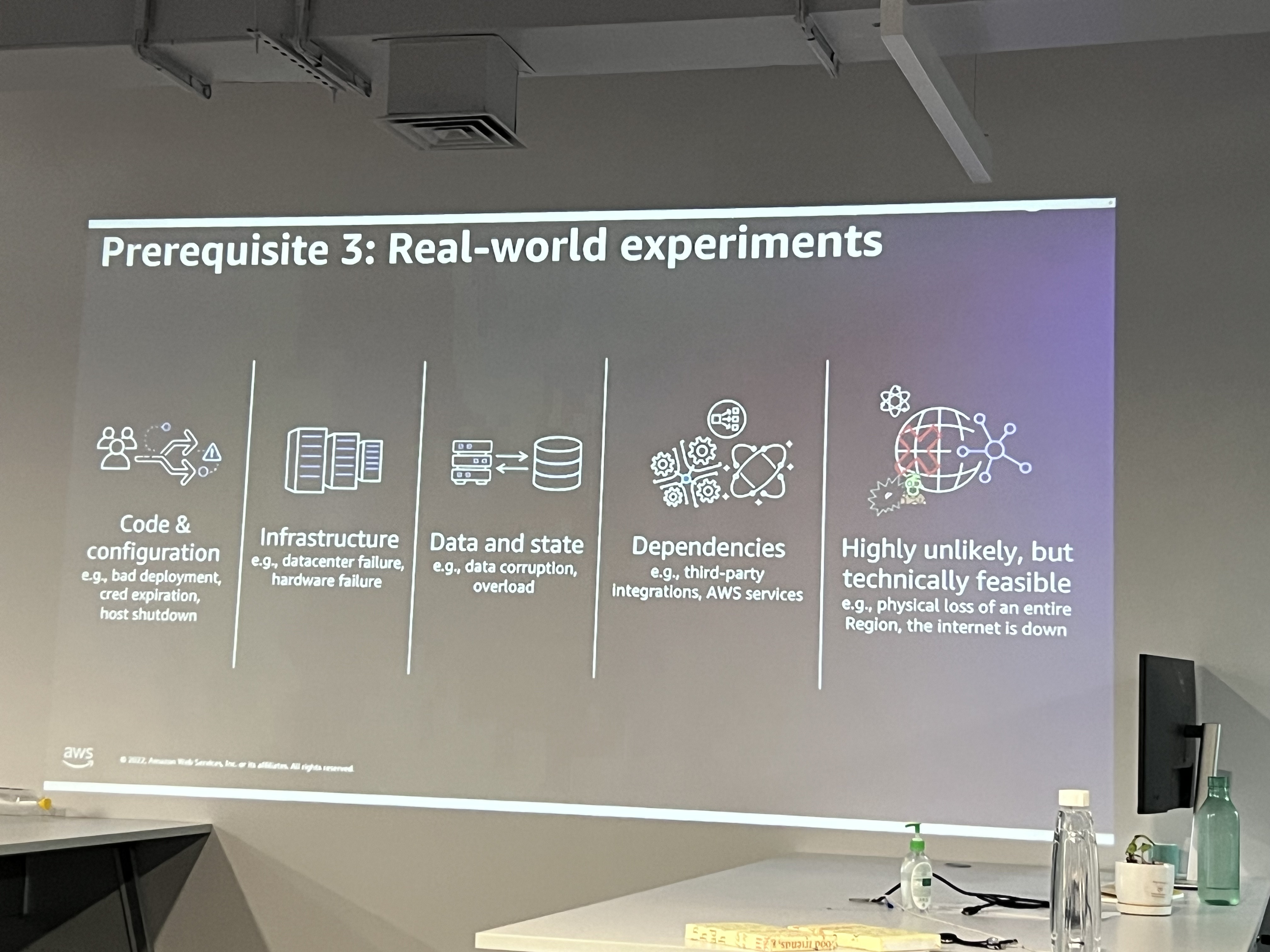
Continuously run experiments to make the system resilient. The speaker defines each aspect of the cycle as given below.
Steady State: Defines normal, healthy operation for the system, including metrics like response times, error rates, and throughput.
Hypothesis: Create hypotheses about how the system will behave when subjected to a failure or disruption. For example, "If the service dependency fails, the system will recover within 2 seconds."
Inject Failure Scenarios: Introduce failure scenarios such as infrastructure failures, dependency outages, or data corruption to test the hypotheses and observe the system's response.
Measure System's Response: Evaluate the system's response to the experiment to check whether it behaved as expected or if there were any unanticipated issues.
Improve: Based on the findings, take corrective actions to improve the system's resilience. This could involve modifying configurations, improving failover mechanisms, or adding redundancy.
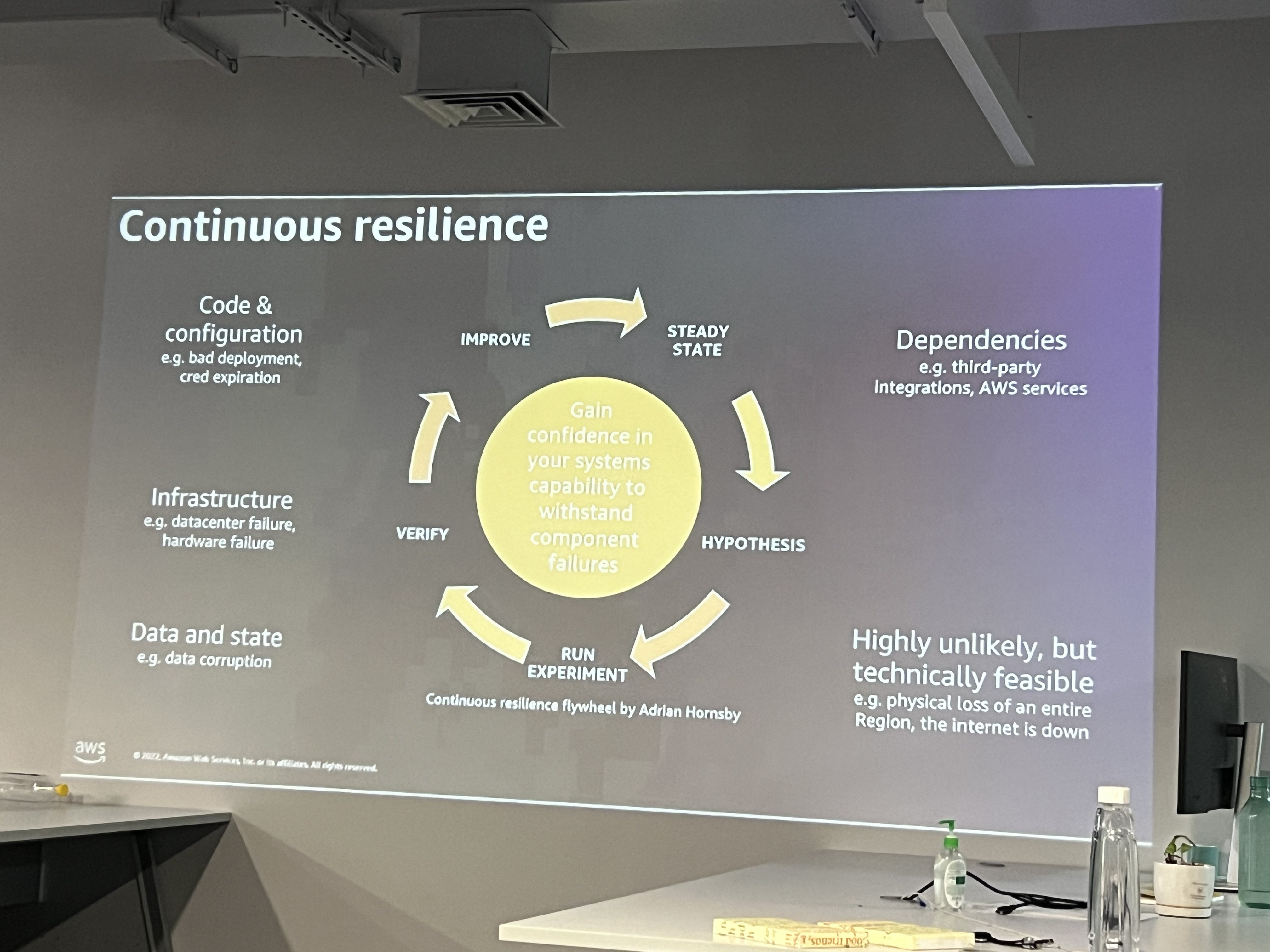
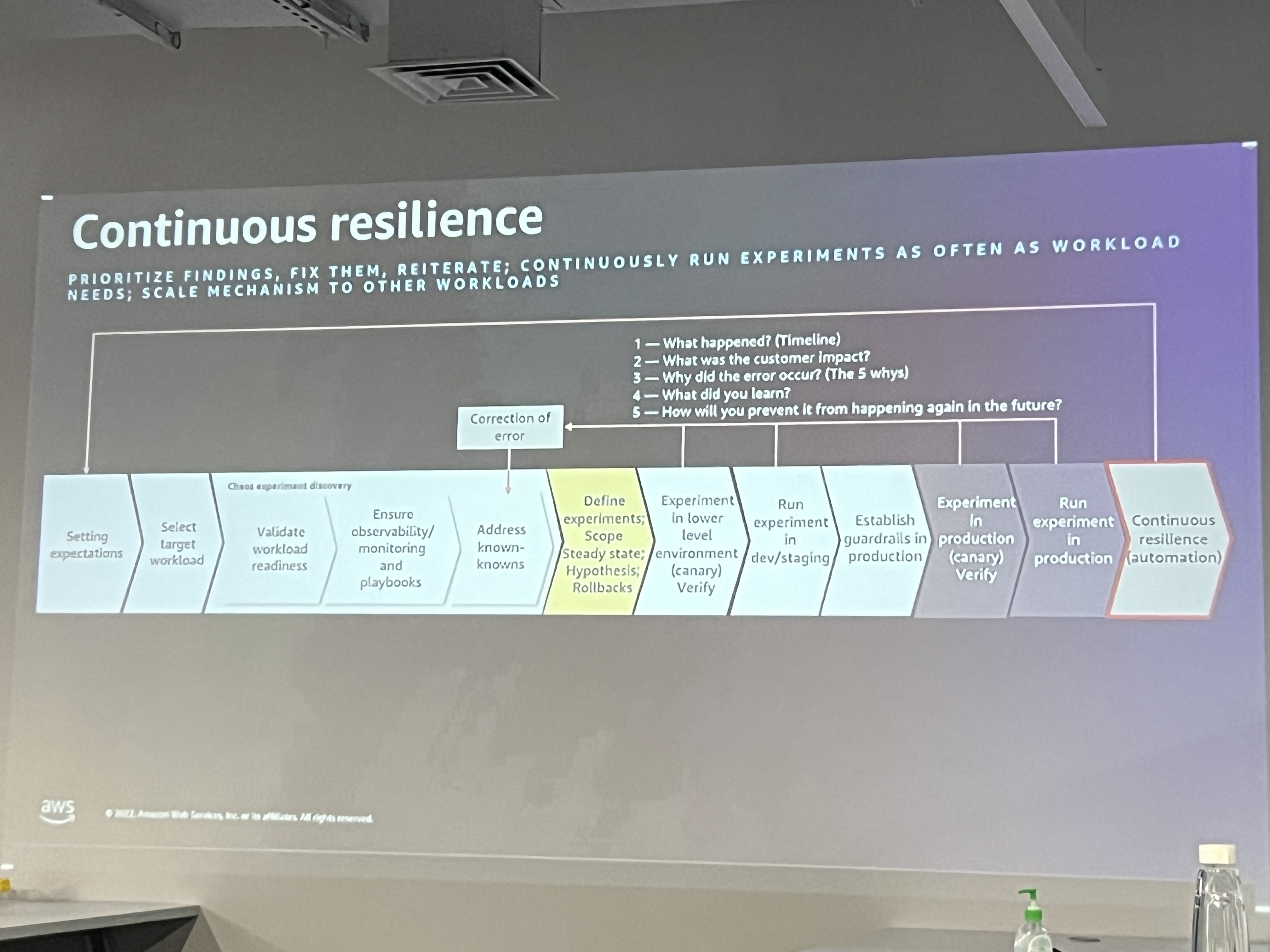
Towards the end, we discussed some popular chaos engineering tools.
Gremlin: A commercial tool that provides various failure scenarios (network disruptions, CPU exhaustion, etc.) to run chaos experiments in cloud or on-premise environments.
AWS Fault Injection Simulator: A service that allows AWS users to simulate infrastructure failures or conditions like latency and I/O bottlenecks in their cloud environments.
Following are some other tools that I found while researching this topic.
Chaos Monkey (by Netflix): One of the earliest chaos engineering tools, Chaos Monkey randomly terminates instances within Netflix's infrastructure to ensure that their services can recover from unexpected instance failures.
LitmusChaos: An open-source tool that helps Kubernetes users orchestrate chaos experiments to test the resiliency of microservices or cloud-native applications.

The session wrapped up with some Q&A, and a bunch of knowledge to take home.
The final session was by Thamizh Arasu, Product Manager at IBM. He made to think about scaling from a different view. The previous sessions were focused on engineering practices but this talk was purely on the importance of why, when and how aspects of scaling.
Foundation Before Expansion: Ensuring Stability Before Scaling
The speaker highlighted that focusing on scaling too early can lead to significant challenges. He went on to explain the key reasons why scaling should not be the initial focus of a business or product.
Scaling should happen only based on business demands, the volume of users, huge transactions, and concurrency. The framework for understanding the "Origin of Scale" in business, focusing on two primary axes:
X-Axis Scale:
This axis represents the expansion of a product or service into new market segments or geographic regions.
Examples include:
LinkedIn, initially a social network for professionals, expanded into job recruitment and learning platforms.
Spotify, originally a music streaming service, added podcasts to its offerings.
Y-Axis Scale:
This axis represents the deepening of a product's penetration within an existing market by targeting additional user segments.
Examples include:
Facebook, starting as a social network for college students, eventually became a platform for the general public.
WhatsApp, initially designed for individual communication, expanded to cater to businesses.
The specific path a business takes to achieve scale will depend on various factors, including market conditions, customer needs, and internal capabilities. As businesses grow and expand, they can gain valuable insights and learnings that can inform future strategies.

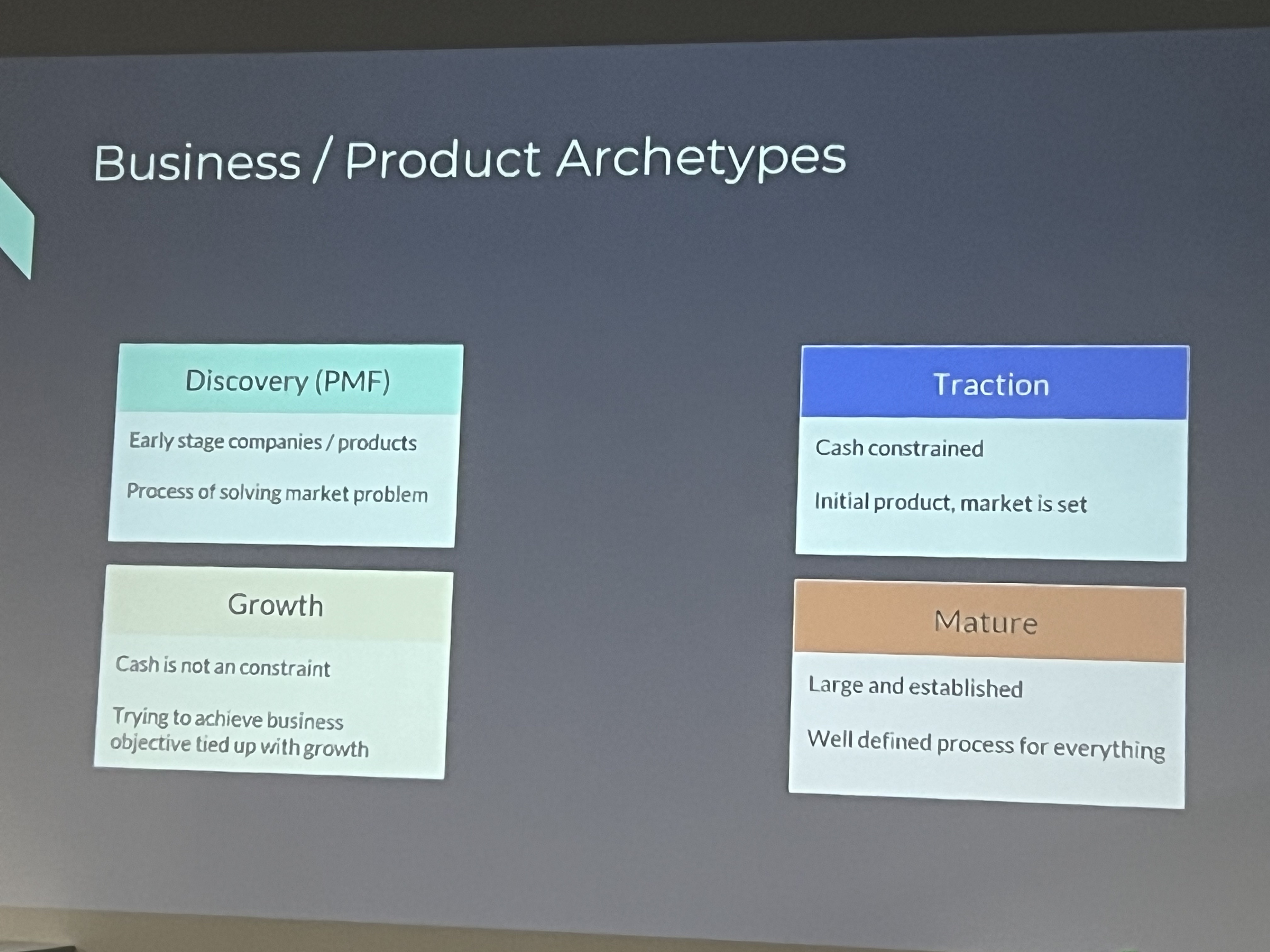
Business/Product Archetypes reflect different stages of a company's or product's lifecycle:
Discovery (PMF - Product/Market Fit)
This stage involves early-stage companies or products.
The primary focus is on solving a market problem and finding the right product-market fit.
Key challenges: Validating the product and understanding whether there is demand for it.
Traction
At this stage, the company is often cash-constrained.
The product is more defined, and the market is set, but the company is still in the process of growing and acquiring more customers.
Key challenges: Scaling operations, acquiring customers, and generating revenue with limited resources.
Growth
In this stage, cash is no longer a constraint.
The company’s primary focus is on growing rapidly and scaling to meet the demands of the market.
Key challenges: Achieving business objectives that are tied to aggressive growth, which might include expanding the user base, increasing revenue, or entering new markets.
Mature
This stage is characterized by being a large and established company.
The company has well-defined processes for everything and has likely optimized operations for efficiency.
Key challenges: Maintaining market leadership, innovating to stay relevant, and handling complex operations.
Finally, the speaker spoke about the lean approach to scaling.
Idea: The process begins with an initial concept or idea for a product or service.
Build: The idea is then transformed into a tangible product or prototype. This involves creating a minimum viable product (MVP) to test the core assumptions of the idea.
Measure: Once the product is built, it's tested and evaluated to gather data on its performance and user feedback. This data is crucial for understanding how the product is being received and identifying areas for improvement.
Learn: Based on the data collected, the team analyzes the results and gains insights into the product's effectiveness. These learnings are then used to iterate and refine the product further.
Repeat: The entire process is cyclical, meaning the team continuously builds, measures, and learns to improve the product over time. This iterative approach allows for rapid experimentation and adaptation to changing market conditions.

That’s a wrap! It was an energetic 2-hour long session full of experiences and insights. All the speakers were engaging, and we had time to network with them and the audience. Post covid, this was my first meetup and it felt great to attend an in-person session as it was more focused and had less scope for diversion, unlike the virtual events. Thanks for reading the post, hope you liked it.



